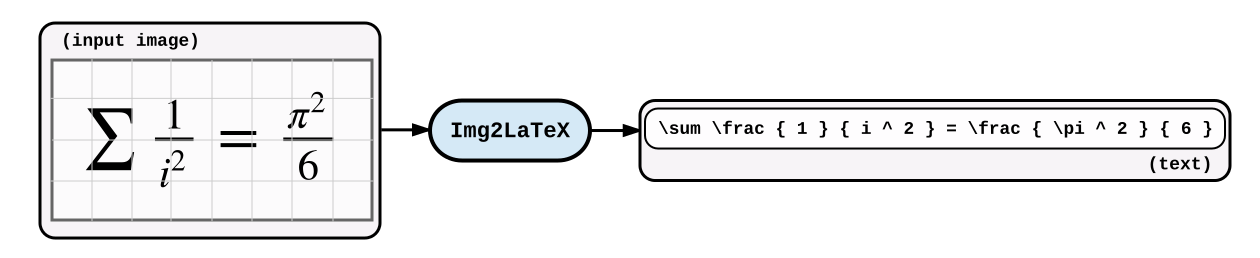
本文是im2latex系列的第二篇,希望能够讲清楚
- 如何将seq2seq模型应用于LaTex生成
- 如何使用Tensorflow实现
请看seq2seq介绍如果你对Seq2Seq还不熟悉。
介绍
作为一名工科学生,我经常问自己:
如果能直接从数学作业的图片里直接生成Latex文件,那该多好啊!
自从我进入斯坦福后,这个想法萦绕心头(我相信不仅光我一个人这么想)我很想自己把它解决了。除了哈佛大学自然语言处理实验室和这个网站外,貌似没有多少可用的方案了。我猜这个问题不是那么简单所以一直等到CS231计算机视觉课开了后处理了这个问题。
这个问题就是如何从图片生成序列的问题,属于计算机视觉和自然语言处理的交叉问题。
方法
第一部分 介绍了sequence-to-sequence在机器翻译中的一些基本概念。同样的模型框架也能应用在我们的Latex生成问题上。翻译问题中的输入序列直接替换成OCR中常用的卷积模型处理后的图片(某种意义上,直接展开图片的像素后作为序列输入的话,完全可以看作翻译问题了)。在图片主题生成上,已经证明这种方法非常的有效(参见Show, Attend and Tell)。在哈佛大学自然语言处理实验室一些工作的基础上,我和我的小伙伴选择相似的思路来做。
在seq2seq模型的基础上,使用卷积网络代替编码器作用在图片上。
这种模型好的tensorflow实现代码不容易找到。结合这篇文章,我发布了相关代码 希望能够有所帮助。你可以用它直接训练你自己的图片主题生成或者其它更高级的应用。这份代码并不依赖于Tensorflow Seq2Seq library—当时tensorflow还没出这个的实现,而且我也想让接口更灵活一些(但能适应相似的接口)。
假定你已经很熟悉第一部分介绍的Seq2Seq模型了。
数据
我们需要大量标注的样本来训练模型:使用LaTex代码生成的公式图片。 arXiv 资源丰富,很多.tex格式的文章都含有LaTeX源码。哈佛大学自然语言处理实验室 使用启发式算法寻找.tex文件中的公式,保留了仅可通过编译的文件,从其中提取了大约100,100个公式。
等等,难道没有发现不同的LaTex代码可以产生同样的图片吗?
很好的问题: (x^2 + 1) 和 \left( x^{2} + 1 \right) 实际上产生的是同样的输出图像。这也是为什么哈佛的文章发现使用解析器 (KaTeX)归一化数据后,能够提升性能的原因。它强制了一些编码转换,比如 x ^ { 2 } 替代了 x^2之类的。经过正则化后,以每行一个公式的形式保存为 .txt 文件,如下:
\alpha + \beta
\frac { 1 } { 2 }
\frac { \alpha } { \beta }
1 + 2
从这种文件中我们可以产生图片: 0.png, 1.png…以及一个映射文件来将图片索引与每行公式做一个映射:
0.png 0
1.png 1
2.png 2
3.png 3
我们之所以使用这种格式主要是因为灵活以及可以使用哈佛大学的预训练数据集 (你可能需要这个预处理脚本)。使用前需要先安装两个包:pdflatex and ImageMagick 。
我们还需要建一个单词表来映射我们的模型输入用到的LaTex字符。以上述的数据为例,这个单词表如下:
+` `1` `2` `\alpha` `\beta` `\frac` `{` `}
模型
我们的模型依赖一种适应图像的Seq2Seq模型。首先,我们定义计算图的输入。不出意外,我们使用一批形如 $[H,W]$ 的黑白图片和公式(Latex字符的字母表id):
# batch of images, shape = (batch size, height, width, 1)
img = tf.placeholder(tf.uint8, shape=(None, None, None, 1), name='img')
# batch of formulas, shape = (batch size, length of the formula)
formula = tf.placeholder(tf.int32, shape=(None, None), name='formula')
# for padding
formula_length = tf.placeholder(tf.int32, shape=(None, ), name='formula_length')
这里需要特别注意图片的输入类型。你可能已经注意到了我们使用的是
tf.uint8. 这是因为图片是灰度图(从0到255:$2^{8} = 256$)。当然我们可以使用tf.float32的Tensor来输入Tensorflow,但是这样会消耗4倍多的内存。数据传输是GPUs的主要瓶颈之一,所以这个小trick可以帮助我们节省很多的训练时间。若要更多利用多线程数据输入,请查看Tensorflow data pipeline。
编码器
High-level idea 在图片上应用卷积网络,输出一个向量序列$[e_{1},… e_{n}]$对应输入图像的相应部分。这些向量将会对应于翻译部分的LSTM的隐层状态。
一旦图片可以转化为序列,我们就可以使用seq2seq模型了。
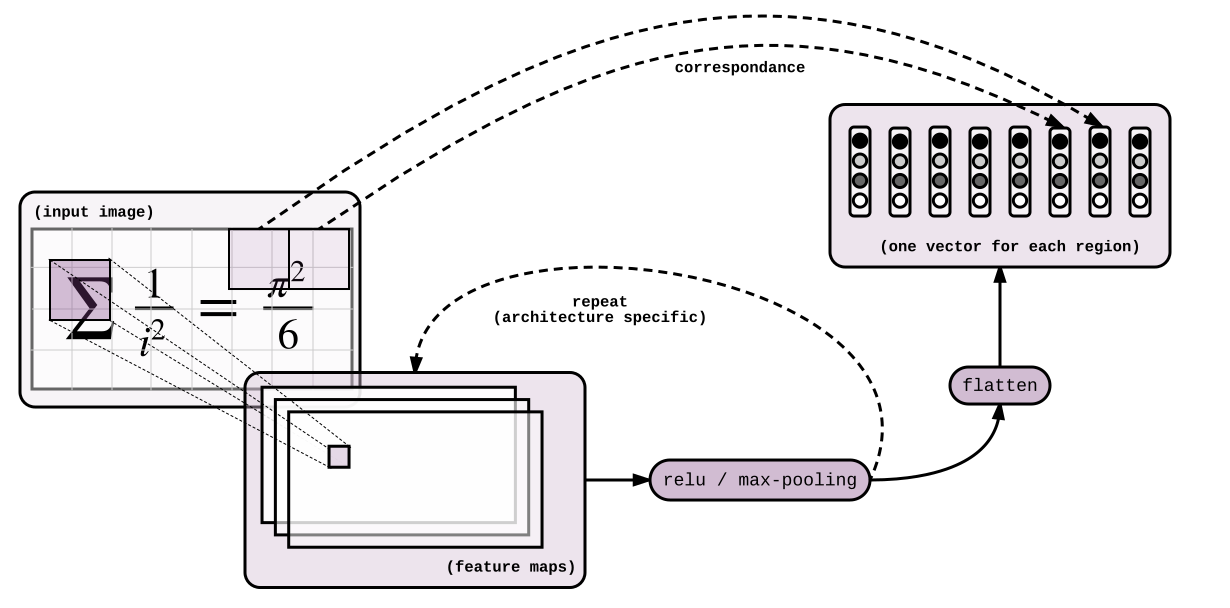
我们需要从图像中提取特征,没什么比(如果有的话,可能是它)卷积神经网络更有效了。其他除了特殊应用与光学字符识别(OCR)的层叠卷积和池化来产生$[H^{t}, W^{t},512]$的Tensor外没有多少好说的,上代码:
# casting the image back to float32 on the GPU
img = tf.cast(img, tf.float32) / 255.
out = tf.layers.conv2d(img, 64, 3, 1, "SAME", activation=tf.nn.relu)
out = tf.layers.max_pooling2d(out, 2, 2, "SAME")
out = tf.layers.conv2d(out, 128, 3, 1, "SAME", activation=tf.nn.relu)
out = tf.layers.max_pooling2d(out, 2, 2, "SAME")
out = tf.layers.conv2d(out, 256, 3, 1, "SAME", activation=tf.nn.relu)
out = tf.layers.conv2d(out, 256, 3, 1, "SAME", activation=tf.nn.relu)
out = tf.layers.max_pooling2d(out, (2, 1), (2, 1), "SAME")
out = tf.layers.conv2d(out, 512, 3, 1, "SAME", activation=tf.nn.relu)
out = tf.layers.max_pooling2d(out, (1, 2), (1, 2), "SAME")
# encoder representation, shape = (batch size, height', width', 512)
out = tf.layers.conv2d(out, 512, 3, 1, "VALID", activation=tf.nn.relu)
这样我们从图片中提取了特征,我们打包图片成序列,这样我们可以使用seq2seq框架。序列长度为$[H^{t} \times W^{t}]$。
H, W = tf.shape(out)[1:2]
seq = tf.reshape(out, shape=[-1, H*W, 512])
你难道不觉得reshape操作会损失很多的结构信息吗?恐怕当使用注意力在图片上的时候,解码器会失去对特征中原始图像位置信息的提取。