动态计算图模型时代
经典的深度学习框架比如caffe,mxnet,tensorflow等都是使用的静态计算图模型(当然最近tensorflow推出新的Execution模式—Eager,mxnet也开始使用新的前端框架Gluon…这是后话),也就是先定义一个计算图,然后往里面“喂”数据,这是经典的Define-and-Run模式…..(我也不知道继续该怎么编了,反正大家都知道怎么用tensorflow和caffe,就是和我们用numpy不一样)直到Chainer横空出世,引入了动态图机制,让深度学习研究工作者眼前焕然一新,pytorch也来了,春天近了。
可以说Chainer的引入的动态图机制是革命性的,不得不佩服日本人开发的这款框架,简介好用,代码基于python,易于阅读,实在是居家旅行不可不少的休闲阅读佳作,这对于连计算图是个啥球的我来说,简直太棒了!不多说了,我们拿出论文(满篇都是日式英语,不知道怎么过的盲审),结合代码,一睹为快。
静态图的问题
现在的深度学习研究进展非常之快,各种网络不断推陈出新,首先我们来看一下目前流行框架的开发团队和他们开发框架的驱动力:
Caffe:贾扬清和伯克利视觉实验室的小伙伴们开发。开始主要是自己用,属于需求驱动。
Torch:Yann LeCun的学生。需求驱动。
Theano:Yoshua Benjio的学生。用于自己科研,但是也发了系统的paper,属于需求+科研驱动。
Tensorflow:Jeff Dean带领的Google员工,主要是系统出身。源于Google在AI领域的布局需求,资本驱动。
Neon:nervana员工,作为创业公司的产品。资本驱动。
MXNet:DMLC(主要是华人机器学习和分布式系统学生)的小伙伴。主要是Minerva,Purine,和cxxnet的开发团队合在一起,一半搞机器学习的,一半搞系统的。需求+兴趣驱动。
剩下还有很多搞系统的人出于兴趣或者科研目的开发的框架,但大多没有流行起来,就不再赘述了。可以看出,除了Google强推的Tensorflow,大多都是从自用和兴趣开始的。而* Tensorflow的开发经费比其他所有框架的经费加起来还要多出几十倍,但是一年下来并没能一统江湖 *。可见需求驱动的力量,所谓“需要是发明之母”。
现在的深度学习框架,已经远远跟不上发展的需求。这使得定义新的网络结构非常的困难:因为现有的框架设计之初是为已经有多那些网络结构来设计的。而且要命的是,大部分的框架使用的DSL(领域特定语言)来定义深度学习模型的(caffe使用的protobuf),然后由框架的解释器转换数据结构。这让开发者调试起来困难多了,远不如像调试原生语言库那样方便。于是克服以上问题的Chainer 诞生了。
Define-and-Run VS Define-by-Run
-
静态计算图定义方式:
我们引入Q-learning的算法流程:这里我们是先定义了一个模型(无论是用猪语言还是caffe的protobuf还是PyLearn2的yaml),然后框架充当一个解释器来把模型转化为
内存中相应的类(definition as object of a single class, which can be regarded as an independent NN),然后程序接收数据,处理加工后输出。
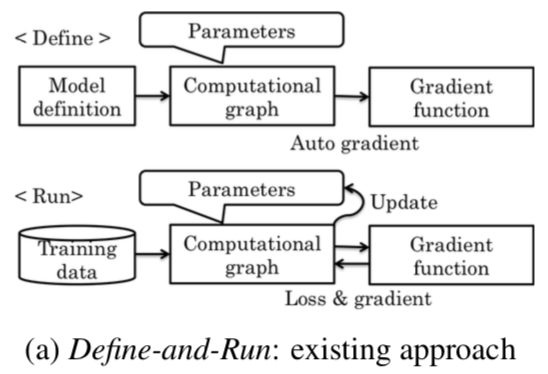
这里问题就出来了: 模型在定义后就占据了内存,内存利用率很低;而且一旦定义后,用户无法在对它进行修改,可扩展性很差(caffe的各种版本已经泛滥成灾);最麻烦的是如何来对它Debug呢?这些框架像一个黑盒子一样,对用户是不可访问的!
- 动态计算图定义方式:
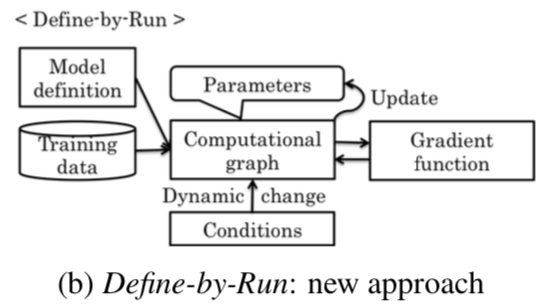
Chainer作为原生的python库(?)让我们可以直接使用pdb就能debug程序。而且整个过程就像曾经写其他原生python代码一样爽歪歪!这里我们定义一个多层感知机

这里,一个计算图在前向计算开始的时候,才真正的被定义了。而上图又显示各个层之间仅有层定义,没有连接起来。在前向计算中,数据在层与层之间流动。
自动求导机制
我们这里以一个超级简单的例子来看一下Chainer的自动求导机制(在我看来,这玩意简直就是沙漠变绿洲的超级黑科技啊)。
# coding: utf-8
import numpy as np
import chainer
from chainer import cuda, Function, gradient_check, report, training, utils, Variable
from chainer import datasets, iterators, optimizers, serializers
from chainer import Link, Chain, ChainList
import chainer.functions as F
import chainer.links as L
from chainer.training import extensions
x_data = np.array([5], dtype=np.float32)
x = Variable(x_data)
print("x: ", x)
y = x**2+x
print("y.data: ", y.data)
y.backward()
print("x. grad: ", x.grad)
在这里,你定义了一个计算通过x得到y,然后backward就能得到导数!这样子我们只需要定义一个网络的结构,无需操心网络的反向过程就行了(当然了,Tensorlow,Pytorch等也有)。
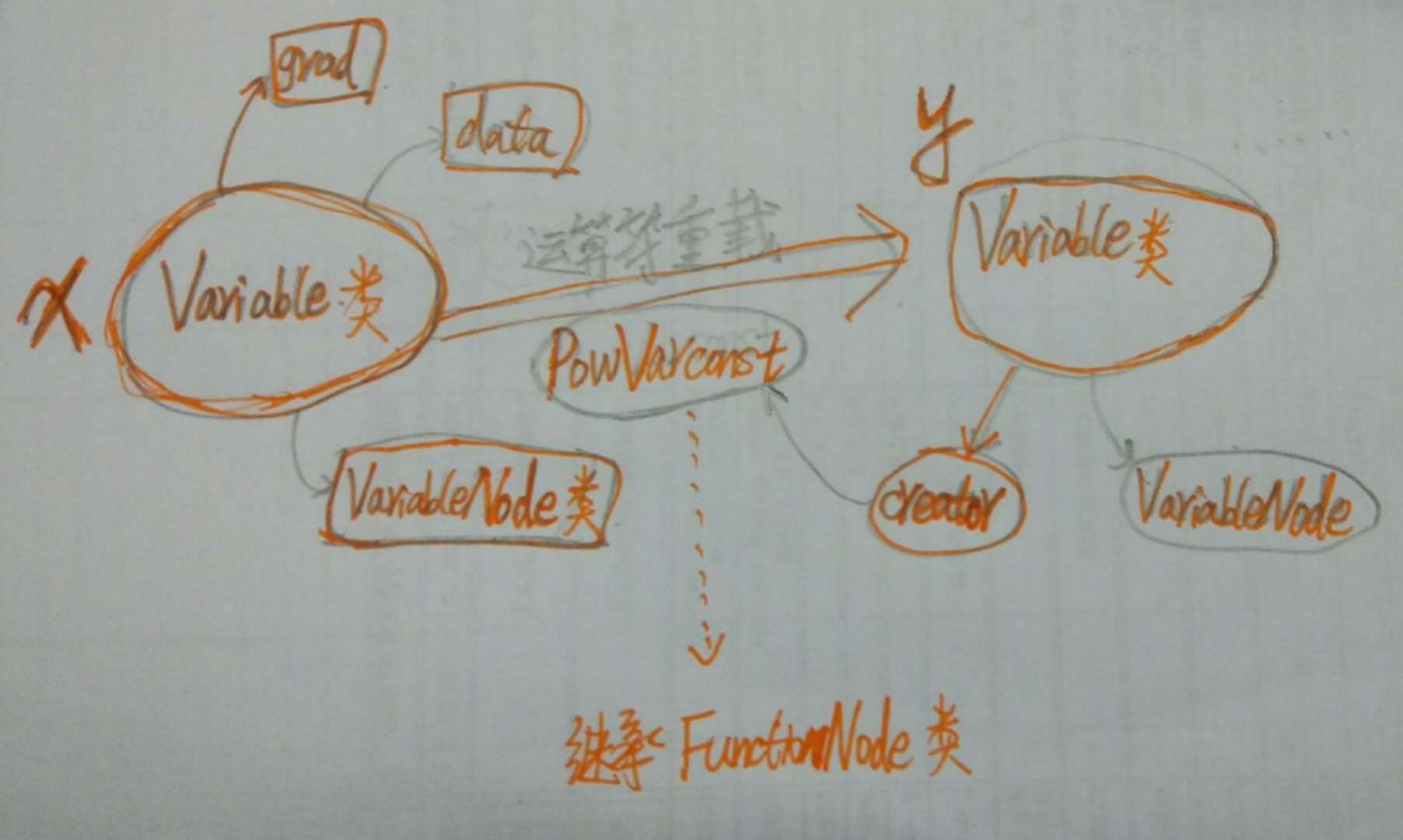
接下来,我们需要打开Pycharm(debug很方便啊),一步一步的看数据的流动,解构反向求导的过程。
##
(未完待续)