
字符级别的识别
早期深度学习在自然语言上的应用比较暴力,直接把数据往CNN里怼。文章Text Understanding from Scratch解释了为啥子CNN也能对文本分类:它先对字符集做了一个类似盲文的编码,将字符编码为定长(l)的向量,然后送入CNN网络来分类。
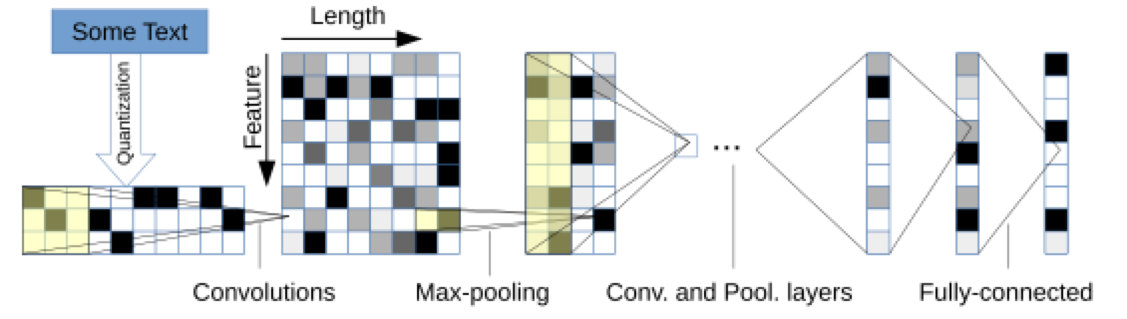
文章厉害的地方在于直接把所有的文本(中文换成拼音)直接怼进去,然后就能取得很厉害的分类结果。表示怀疑,有空了重复实验。还有一篇文章CNN for Sentence Classification稍有改进,把文本进行word embedding后,再送入了CNN。
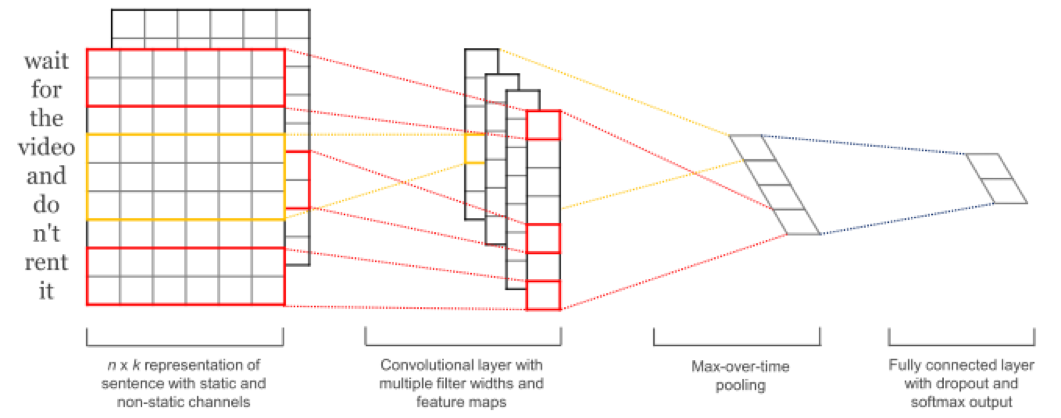 ,Max-pooling后得到固定长度的feature map。
,Max-pooling后得到固定长度的feature map。
A C-LSTM for Text Classification更进一步,将卷机后的feature maps送入了window feature sequence后再送入LSTM。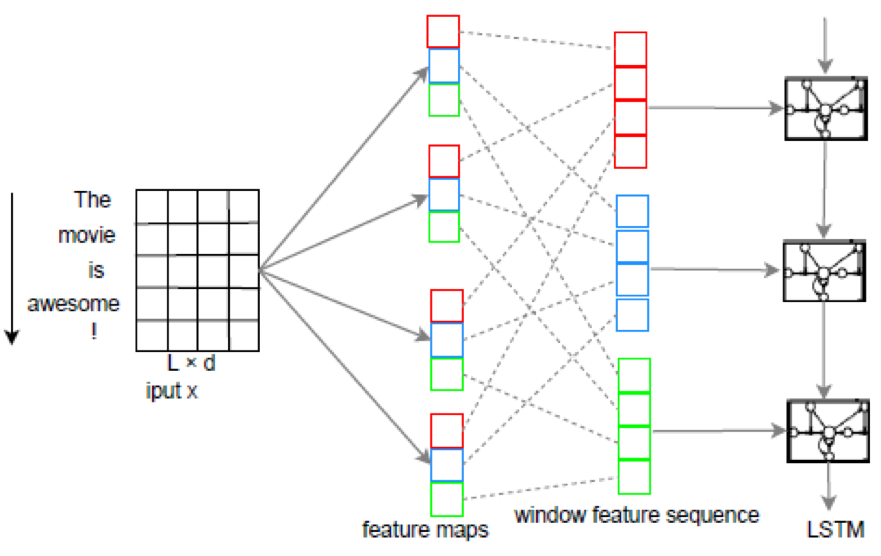
优点在于既能捕获局部特征,又能学习到语义表达。不过针对其他的RNN,CNN变形结构,没有什么明显的优势。
句子级别的识别。
循环(Recurrent)卷机神经网络针对句子过长时,网络无法有效结合上下文信息来表达信息,创造性地提出结合word的上下文来表达每个word的信息 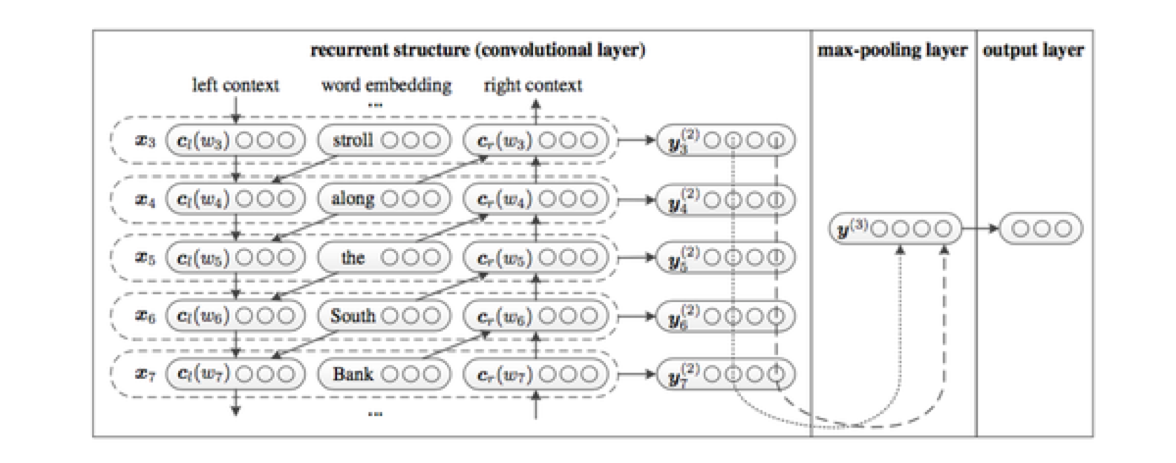
公式表述也很简洁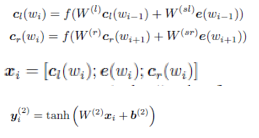 。
。
文档级别
最近大热的注意力机制很是风骚啊,Hierarchical attention networks for Document Classification
这篇文章最屌的地方在于可以对复杂句进行分类,明明看上去像是褒义的句子,但是它能够辨识出这是反讽!精度上就更不用说了。
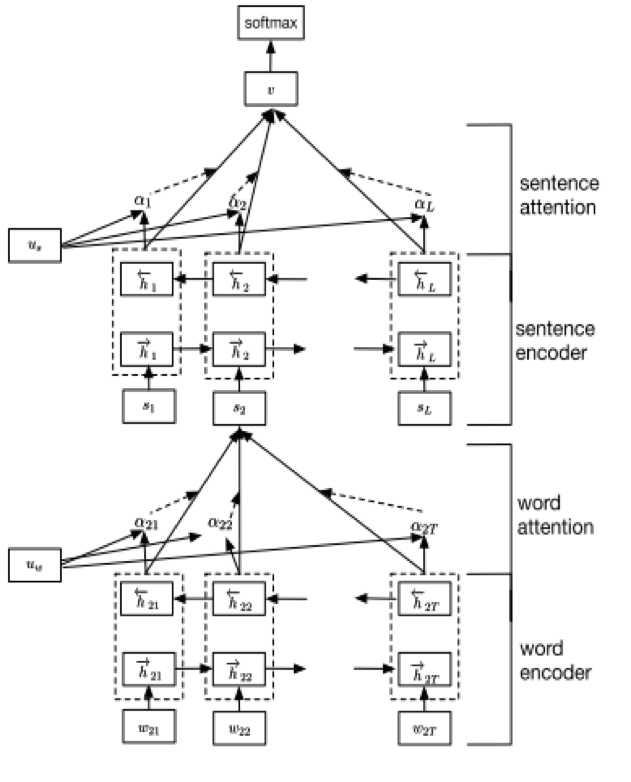 。
。
虽然图画的很复杂,但是代码还真心没有几行的。我们可以再来分析分析它的代码。
太忙了,占坑,过几天再填